時系列解析で,長時間相関といえば長時間自己相関を意味することがほとんどです.つまり,1本の時系列の性質を考えています.

ここでは,1本ではなく,2本の時系列が共通に持つ特性として,長時間相互相関の分析法を紹介します.
そこで登場するのが Detrending Moving-average Cross-correlation Analysis (DMCA)です.詳しいことは以下の論文に説明してあります (ラグの推定法はイマイチなので使わないでください).
今回は,Rで,なんとなくDMCAをやってみます.
数値実験でDMCA
以下のスクリプトでは,2つの時系列 x1と x2が共通の長時間相関成分 eps.commonを含んでいます.DMCAを使うことで,共通の成分の有無の評価と,eps.commonのスケーリング指数を推定できます.
#
# Higher-order detrending moving-averagecross-correlation analysis
# 0次DMCAのデモ (ラグなし)
# 【実際の解析ではラグの推定が重要です】
#
######################
# 事前に以下の2つのパッケージをインストールすること
# install.packages("longmemo")
# install.packages("signal")
######################
require(longmemo)
require(signal)
######################
# 時系列の生成に使うパラメタ
# 時系列の長さ
n <- 10000
# Hurst指数の指定
H.common <- 0.75
H1 <- 0.55
H2 <- 0.95
################
# 共通成分のSD
SD.common <- 0.8
################
# scaleは平均0,標準偏差1にする関数
eps.1 <- scale(simFGN0(n,H1))[,1]
eps.2 <- scale(simFGN0(n,H2))[,1]
eps.common <- scale(simFGN0(n,H.common))[,1]*SD.common
###
x1 <- eps.1 + eps.common
x2 <- eps.2 + eps.common
############################
par(mfcol=c(3,2),las=1,cex.axis=1.2,cex.lab=1.5,mar=c(5,5,3,1),cex.main=1.6)
plot(1:n-1,x1,"l",col=3,xaxs="i",xlab="i",main="Sample time series")
lines(1:n-1,eps.common,col=rgb(1,0.4,0.3,alpha=0.6))
plot(1:n-1,x2,"l",col=4,xaxs="i",xlab="i",main="Sample time series")
lines(1:n-1,eps.common,col=rgb(1,0.4,0.3,alpha=0.6))
plot(1:n-1,eps.common,"l",col=2,xaxs="i",xlab="i",main=sprintf("Common input signal: H=%.2f",H.common))
############################
# スケールを何点とるか
n.s <- 20
# スケールの決定 (DMAで解析するスケールは奇数のみ)
s <- unique(round(exp(seq(log(5),log(n/10),length.out=n.s))/2)*2+1)
# スケール数の再計算 (重複があるので減る)
n.s <- length(s)
#########################
F1 <- c()
F2 <- c()
F12_sq <- c()
# 【STEP1 】時系列の積分
x1 <- x1 - mean(x1)
x2 <- x2 - mean(x2)
y1 <- cumsum(x1)
y2 <- cumsum(x2)
# 0次DMAとDMCA
for(i in 1:n.s){
# Detrending
y1.detrend <- y1 - sgolayfilt(y1,p=1,n=s[i],m=0,ts=1)
y2.detrend <- y2 - sgolayfilt(y2,p=1,n=s[i],m=0,ts=1)
F1[i] <- sqrt(mean(y1.detrend^2))
F2[i] <- sqrt(mean(y2.detrend^2))
F12_sq[i] <- mean(y1.detrend*y2.detrend)
}
rho <- F12_sq/(F1*F2)
#####
# plot
###
# 相互相関
plot(log10(s),rho,col=2,ylim=c(-1,1),main="Cross-correlation")
abline(h=c(-1,0,1),lty=2,col=gray(0.5),lwd=2)
# スケーリング
log10F1 <- log10(F1)
log10F2 <- log10(F2)
log10F12 <- log10(abs(F12_sq))/2
y.min <- min(log10F1,log10F2,log10F12)
y.max <- max(log10F1,log10F2,log10F12)
#
plot(log10(s),log10(F1),col=3,pch=2,xlab="log10 s",ylab="log10 F(s)",ylim=c(y.min,y.max),main="Scaling")
points(log10(s),log10(F2),col=4,pch=3)
points(log10(s),log10(abs(F12_sq))/2,col=2,pch=1)
############
# 傾きの推定
log10s.min <- 1.5 # 区間の下限
log10s.max <- 2.5 # 区間の上限
lfit <- lm(log10F12[log10(s) >= log10s.min & log10(s) <= log10s.max]~log10(s)[log10(s) >= log10s.min & log10(s) <= log10s.max])$coefficients
curve(lfit[[1]]+lfit[[2]]*x,xlim=c(log10s.min,log10s.max),add=TRUE,col=2,lty=2,lwd=2)
abline(v=c(log10s.min,log10s.max),col=gray(0.6),lty=2)
legend("bottomright",legend=c(sprintf("Estimated slope:%.2f",lfit[[2]])),lty=c(2),col=c(2),lwd=c(2))
############
plot(log10(s)[-1],diff(log10F1)/diff(log10(s)),col=3,pch=16,xlab="log10 s",ylab="local slope",ylim=c(0.4,1.1),main="local slope estimation")
points(log10(s)[-1],diff(log10F2)/diff(log10(s)),col=4,pch=16)
points(log10(s)[-1],diff(log10F12)/diff(log10(s)),col=2,pch=16)
abline(h=H.common,lty=2,col=rgb(1,0.4,0.3,alpha=0.6))
legend("topleft",legend=c(sprintf("Theory: H=%.2f",H.common)),lty=c(2),col=c(rgb(1,0.4,0.3,alpha=0.6))) 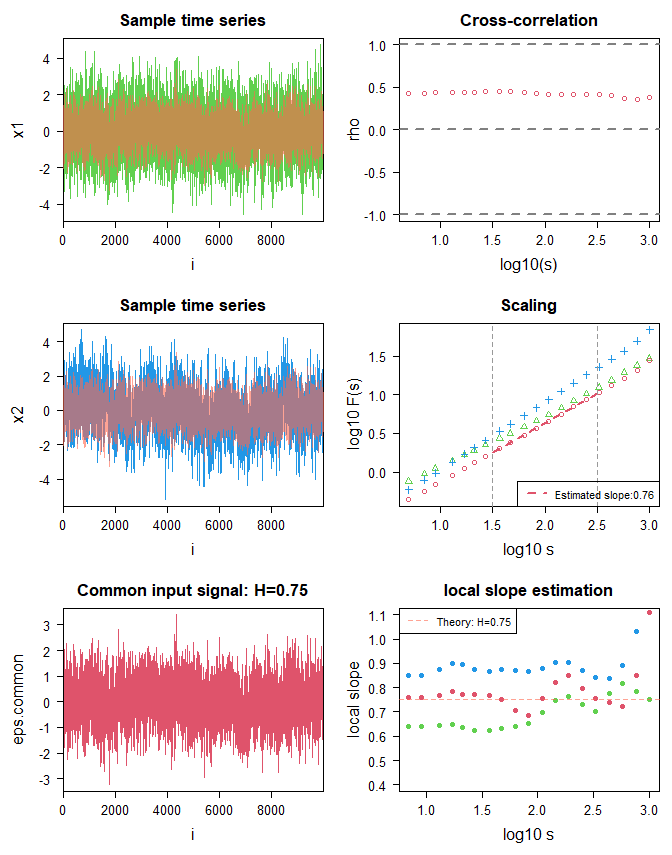
Rスクリプトを実行して描かれる図について簡単に説明します.左の上から2段の緑と青の線が,それぞれ,サンプル時系列 x1と x2です.透明ピンクで描いてあるのが,共通成分 eps.commonです.左下にも eps.commonがプロットしてあります.
図の右上が,
です.右の中央に,赤で,緑で
,青で
がプロットしてあります.
右下はおまけで描いた,局所スロープのプロットです.
式の定義は,最初にあげた論文をみてください.
あとがき
DFAとか,DMAとか,DMCAとかの,数理的な基礎をきちんと理解したいと考えて,理論的な部分を構築している研究者は,私を含めて5人くらいじゃないでしょうか.みんなに基礎の面白みをわかってほしいですが,ほとんどの人は飽きて眠くなってしまいます.興味があれば,ある程度詳しく説明するので質問してください.